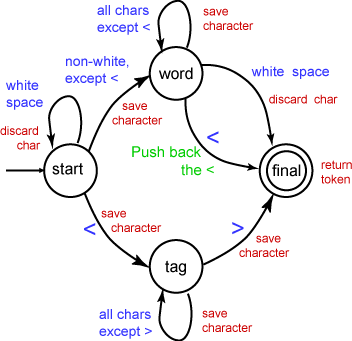
Now examine the nextToken method.
The states of the automaton are represented
as integers.
The final state is not actually implemented;
when the automaton reaches the final state,
the method returns to its caller.
The scanner reads characters one at a time
until it reaches the final state or hits
end of file (signaled by a -1).
If it hits end of file, it returns null.
While in the start state, the scanner skips over
white space.
The first not-white character causes a transition
to the word state or the tag state.
The first character of the token is stored
in the buffer.
While in the tag state, the scanner
gathers up characters for the tag token
until it sees a > character.
Then it ends to tag with that character
and returns the tag token to the caller.
While in the word state, the scanner
gathers up characters one by one
until it sees a whitespace character or
a < character.
When the word state sees a whitespace character
it returns the token to the caller.