




No.
In the previous chapter,
after a subroutine is called,
the return address to main is
in register $ra.
If that subroutine calls another subroutine,
the address in $ra is changed
and the return address to main is lost.
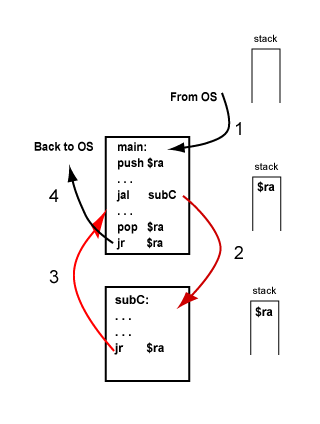
To
return to the caller
a subroutine must have the correct
return address
in $ra when
the jr instruction is performed.
But this address does not have
to remain in $ra
all the time the subroutine is running.
It works fine
to save the value in
$ra on the stack.
The value can be restored, later on, when
it is time to return to the caller.
In the picture,
QTSPIM starts
main
(step 1)
then main
calls subA
with a jal instruction
(step 2).
This puts the return address to main
in $ra.
When it gets control,
subA
pushes the return address on the stack
(step 3).
The return address that subA
should use when it returns to main
is now on the top of the stack.
The "push" and "pop" instructions in the picture are conceptual. Actual code does these operations in the usual way.
After pushing the return address,
subA runs for a while.
Then subA calls subB
using a jal instruction (step 4).
This puts the return address to subA
in $ra.
subB receives control
and pushes $ra on the stack
(step 5).
The return address that subB must use is now
safely on the top of the stack.
subB now runs for a while.
When subB returns to subA
it pops the return address from the stack
into $ra.
It then uses a jr $ra instruction (step 6).
The top of stack is now the return address to main.
Control returns to
subA,
which runs for a while.
subA returns to main
by popping the stack into $ra
and executing
a jr $ra instruction (step 7).
Control returns to main.
The stack is now logically empty.
The return addresses have been popped in the reverse
order that they were pushed.
The program ends when
main uses exception handler
service 10 (step 8).
The most recent version of QtSPIM requires
main to end by using exception handler service 10.
(Thought Question: )
subB did not change $ra.
It could have used it with jr
as is is.
Why bother pushing it?