


Answer:
No, its better design to have a URL extractor module and a URL user module. Then the first module can be used in other programs (for example, a web-crawler).
No, its better design to have a URL extractor module and a URL user module. Then the first module can be used in other programs (for example, a web-crawler).
Recognizing URLs is easy (with our simplified rules),
as seen in the following automaton.
White space is not allowed inside the URL,
so after the http:// part the automaton
accepts characters up to the first whitespace character.
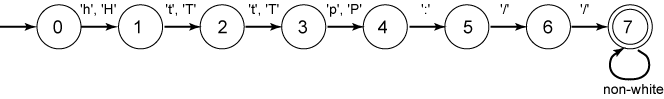
The automaton as shown above halts if the input string is not a URL. But we don't want the scanner to halt. When it is called, we want it to skip over characters until it reaches a URL, then collect the characters of the URL until it reaches the end of the URL. Then the scanner should return the URL to the caller.
Mentally add state transitions that:
(1) Skip over non-URL characters, and
(2) Return to the caller at the end.